12.02.2018Лось квайн
Давненько я не писал чисто программерского! Есть такая прекрасная маргинальная область: бесполезная дурня. Для меня — это совершенно точно искусство, как оно есть, только для очень узкого круга людей. Более ли менее известный пример — это Simone Giertz – Королева говёных роботов. Я сам бесконечно уважаю бесполезную дурню. О некоторых штуках я даже писал ранее. Например, про лося в терминале или про JSFuck. Сегодня хочу рассказать про моё свежее улечение — квайны. И похвастаться, конечно.
Про программы, которые выводят собственный текст, я слышал уже давно. Это казалось чем-то очень навороченным и неприступным. Если нет специальной функции для этого и нельзя читать файл, то не совсем понятно, с какого бока начинать. Но тут как раз перед выходными мне прислали статью, которая подводит под это дело теоретическую базу. В силу не совсем профильного образования, мне не довелось серьёзно заниматься теорией вычислений, а это оказалась довольно прикольная область.
И вот, наступил викенд, и меня сильно это дело вштырило. Вооружившись теоретическим доказательством того, что на любом языке программирования можно написать квайн, я приступил к составлению своего корявого решения. К концу выходных я написал двухступенчатый квайн, который при каждом запуске выводит следующий шаг моего лося из репортера.
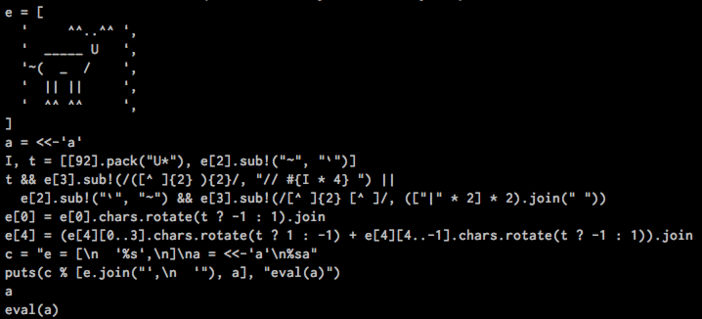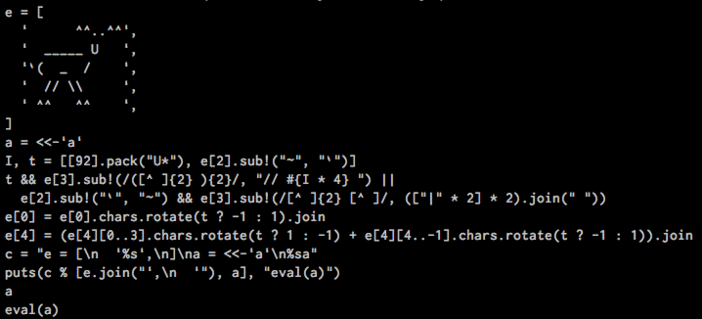
В силу личного склада, это походило на зависимость. Чуть голова не разболелась. Главное в это деле — вовремя остановиться. Сейчас в репозитории есть усовершенствованная версия с гифки выше, версия, которая анимирует пробег лося по парамтерам, а так же версия в технике аски-графики. Примечательно, что не смотря на отсутсвие примеров, я пришёл к оптимальному варианту, который многие используют, когда хотят чтобы квайн, кроме своей непосредственной функции делал ещё что-то такое же бесполезное и прекрасное.
eval a = <<-'a'
# Мой код
puts "eval a = <<-'a'\n#{a}a"
aПосле пошёл читать код такого же любителя странного — Юсуке Эндо (Yusuke Endoh). Он, среди прочего, написал квайн-реле, которое выводит на каждом шагу код на другом языке. И если его запустить на 128 языках 128 раз, то оно выведет обратно исходный код на первом языке. Чувак тоже относится к программированию как к искусству. Странному, гиковскому, маргинальному, нердическому, но при этом Великому и Бессмысленному Искусству. Например, он написал книгу, которая называется «The World of Obfuscated, Esoteric, Artistic Programming». Конечно же, на японском. И врядли её переведут ( ≧Д≦) Или у него есть «Квайн, устойчивый к радиации», из которого можно удалить одну любую букву и он при запуске выведет восстановленный исходный код. Ещё и в аски-графике.
Вот вам видео последней версии квайна, вдохновленное товарищем Эндо. Отлично провёл время, в общем. А у вас как дела?
Материалы для самостоятельного изучения
16.03.2016Как я встраивал reCAPTCHA v2 в свой антикварный бложек
Предпосылки
Мы живём в интересное время. Когда я увлекался довольно серьёзно руби он рэйлз, лет шесть-семь назад, была версия руби 1.8.7 и версия рельсов 2.3. Все неспешно переходили на руби 1.9.1 и рэйлз 3.0. Сегодня, пять лет спустя, стабильная версия руби — 2.2.3, а про рельсы уже агитируют переходить на 5.0, хоть и бета. Когда же я начал свой первый проект на ноде — три года назад, — версия node.js была что-то типа 0.22. А сегодня уже 5.8!
А недавно имел разговор с читателем на тему того, что стремительно возросшая популярность джаваскрипта создаёт ситуацию, при которой, уходя в отпуск, программисты рискуют вернуться с устаревшими навыками, потому что за две недели появились три новых прекрасный фреймворка, а два не менее прекрасных — умерли.
Антиквариат
До последнего перерыва, рассказ о начинке моего блога мог бы легко заполнить парочку в меру интересных статей, а сейчас это представляет интерес только для археологов. Что касается движков для блога вообще, то про когда-то популярный ЖЖ все уже забыли. Стремительно набирает моду вести канал в Телеграме. А товарищ мой — Илья — в когда-то давно в качестве платформы для блога сделал самый правильный, как мне сегодня кажется, выбор — генератор статического сайта.
Что ещё? Технология оупенайди, на которой у меня были прикручены комментарии, умерла. Рекапча, которую я прикручивал в комментарии Ире, была куплена Гуглом и ещё пока жива, но уже выпустили вторую версию, и я боюсь, как бы они таки не закрыли первую, как Гугл это умеет делать. Но даже тогда джем, который я использовал, чтобы встроить капчу, волшебным образом исчез из библиотек, и мне пришлось таскать его с собой в папочке vendor. Про вёрстку я даже не говорю.
В общем, для того, чтобы взять и переписать проект с нуля, много ума не нужно. Но сегодня мне интересно покопаться в старье и посмотреть, что ещё из него можно выжать. Поэтому, если вы любите свои старые поделки так, как люблю их я, то очень важно овладеть навыком написания обезьяньих заплаток (monkey patch).

reCAPTCHA v2
Когда я решил использовать новую капчу, я даже не стал искать библиотек. С вероятностью 80% они не заработают на моей старинной системе, и с вероятностью 30% перестанут поддерживаться очень скоро. Просто читаем документацию, встраиваем капчу в форму отправки комментария, а на сервере прямо в методе создания комментария пишем, например:
url = URI.parse('https://www.google.com/recaptcha/api/siteverify')
req = Net::HTTP::Post.new(url.path)
req.set_form_data 'secret' => 'SECRET_KEY',
'response' => params['g-recaptcha-response'],
'remoteip' => request.remote_ip
https = Net::HTTP.new(url.host, url.port)
https.use_ssl = true
https.verify_mode = OpenSSL::SSL::VERIFY_NONE
res = JSON.parse(https.start { |p| p.request req }.body)
if res['success'] ...И далее с ответом можно делать всё, что угодно. В тонкости уже не вдаюсь, потому что, как может увидеть дорогой читатель, даже хэши у меня написаны с ракетами, а не по-современному с двоеточиями.
Да, это противоречит паттерну MVC, да, это противоречит ООП. Но посмотрите на саму капчу: она не учитывает положения формы на странице, когда открывает своё окно. А также не работает задокументированная фича data-tabindex. Полно хороших библиотек и поделок увядают так и не исправив своих ошибок. Такова реальность программиста сегодня. Красивая библиотека для встраивания в проект на рельсах не сделает эту капчу лучше, но исправлять описанные выше ошибки можно тоже обезьяньими заплатками.
В общем, есть, конечно, определённый кайф в том, чтобы сделать всё максимально по науке и близко к идеалу, но не менее приятно пользоваться смекалкой и собрать что-нибудь из грязи и палок. Безусловно, есть ещё и очень приятное чувство освобождения в том, чтобы разрешить себе делать что-то не идеально.
18.05.2011Использование руби программ в качестве фильтров для поиска
Предыстория
Не далее как прошлой осенью я писал о том, как изнутри процесса определить, запущен ли он, используя инструмент grep. В комментариях мне посоветовали использовать pidof, но мне не удалось заставить его работать для руби, т.к. поиск происходит по имени запускаемого файла, а в случае руби-скрипта это всегда ruby. Но мне существенно удалось сократить получение списка запущенных процессов с таким же именем. Вместо:
`ps ax | grep #{File.basename(__FILE__)} | grep -v grep`.split("\n").map{ |l| l.strip.split(/\s+/)[0].to_i }.reject{ |pid| pid == Process.pid }получилось
`pgrep -f #{File.basename(__FILE__)}`.chomp.split(/\s+/).reject{ |pid| pid.to_i == Process.pid }Довольно часто мне необходимо отфильтровать вывод или содержимое файла хитрее, чем просто поиск по регулярному выражению. Поскольку мне очень нравится руби, и, как неоднократно писалось в этом блоге, я пытаюсь использовать его везде, где можно, то почему бы снова так не поступить?

Командная строка руби
Руби имеет умеренное количество ключей командной строки. Кратко они описаны в выводе:
ruby --helpНас в большей степени интересуют ключи -n и -p, которые создают цикл вокруг чтения из пайпа. Ссылка на подробности — в конце статьи.
Например, мы хотим посчитать, сколько всего виртуальной памяти занимают все процессы браузера гугл-хром. В качестве источника информации будем использовать вывод команды:
ps axo "%p %z %c"В которой собраны только необходимые данные (занимаемая виртуальная память и имя процесса без аргументов) и пид (ну а вдруг?). А теперь этот вывод отправим не грепу, а нашему родному руби:
ps axo "%p %z %c" | ruby -nae 'num ||= 0; num += $F[1].to_i if $F[2] =~ /chrome/; END{puts "total chrome virtual memory size #{num} Kbytes"}'Что это означает? Ключ n означает, что вокруг нашего скрипта есть цикл вида:
while gets(); ... endКлюч a означает, что вместо переменной $_, куда автоматически попадает результат gets, мы можем использовать $F, который есть суть $_.split. А END содержит блок, который выполняется после цикла.
Ту же магию можно использовать и внутри запускаемых руби-скриптов. Например, если мы хотим найти какое-то слово внутри файла, выделить его цветом и вывести строку с номером, где это слово нашлось, то наш скрипт будет выглядеть вот так (файл look_for):
#!/usr/bin/ruby -n
BEGIN {
unless ARGV.size == 2
puts "Usage: ./look_for <word> <path/to/file>"
exit
end
str = ARGV.shift
}
next unless $_ =~ /#{str}/
printf "%6s%s", $., $_.gsub($&, "\e[31m#{$&}\e[0m")Теперь, если сделать этот файл запускаемым и запустить его:
./look_for word /in/some/fileТо можно увидеть неземную красоту. Кстати, обратите внимание на shift. Без него программа не работает, т.к. gets, который тут за кадром правит бал, пытается воспринимать все аргументы как пути к файлам, из которых непременно нужно что-нибудь прочитать.
Прочие прекрасные применения параметров командной строки руби я предлагаю пытливому читателю подсмотреть в ссылках ниже или найти самостоятельно.
Материалы для самостоятельного изучения
23.03.2011Рекурсия в регулярных выражениях
Пролог
Что-то большие перерывы в написании статей входят в привычку. Способность некоторых коллег по цеху регулярно выдавать что-нибудь полезное и интересное вызывает уважение.

Введение
С тех самых пор, как я только узнал про регулярные выражения, я слышал об их несовершенстве и моральном устаревании. Регулярные выражения продолжали использоваться, а недовольные теоретики — сетовать. Основной претензией было то, что регулярные выражения не позволяют исследовать вложенности паттернов в виду своей линейности. Действительно, соглашался я, невозможно проверить правильность открытия и закрытия тегов или получить выражение в самых внутренних скобках.
Однако, как оказалось, человечество шагнуло далеко вперёд в вопросе совершенствования регулярных выражений. Об одном из новшеств хочу сегодня рассказать.

Именованные группы
В регулярных выражениях руби 1.9 появились именованные группы. Вот, как выглядит их элементарное использование:
if /\A(?<first>[a-zA-Z]+)\s+(?<last>[a-zA-Z]+)\Z/ =~ "Vassily Poopkine"
puts [first, last].inspect
end
if md = /\A(?<first>[a-zA-Z]+)\s+(?<last>[a-zA-Z]+)\Z/.match("Vassily Poopkine")
puts [md[:first], md[:last]].inspect
endТо есть мы не только выделяем группу скобками, как обычно, назначая ей тем самым порядковый номер (по номеру открывающей скобки), но и даём имя. И использовать его можно не только в локальных переменных и объекте MatchData, но и в самом регулярном выражении.
Более того, обращение к объявленным группам внутри может быть рекурсивным. Мне сразу же захотелось написать давнишнюю мою задумку о функции, раскрывающей вложенные скобки. Вот так:
str = "1 + 2 * (3 - 4 / {5 + 6} + [7 - 8 * (9 + 10 * 11) + 12 * {13 - 14}] + 15) + 16 * (17 + 18)"
re = %r{
(?<fill>[0-9+\-*/\s]+){0}
(?<expression>\g<fill>*\g<brackets>\g<fill>*|\g<fill>){0}
(?<braces>\{\g<expression>+\}){0}
(?<squarebrackets>\[\g<expression>+\]){0}
(?<parentheses>\(\g<expression>+\)){0}
(?<brackets>\g<braces>|\g<squarebrackets>|\g<parentheses>)
}x
def calculator(str)
if str =~ /\A[0-9+\-*\/\s]+\Z/
eval str
else
raise "Invalid expression: #{str}"
end
end
f =-> s do
if $~[:expression] == $~[:fill]
calculator($~[:fill])
else
calculator($~[:brackets][1..-2].gsub(re, &f))
end
end
puts calculator(str.gsub(re, &f))
puts eval(str.gsub(/(?<left>\{|\[)|\}|\]/) { |s| $~[:left] ? "(" : ")" })Итак, в регулярном выражении присутствует 6 именованных групп: fill (заполнения пространства между скобками), expression (выражение, содержащее одни или ни одних нераскрытых скобок), braces (фигурные скобки), squarebrackets (квадратные скобки), parentheses (круглые скобки), brackets (любые скобки). Как видите, выражение описывается через скобки, а скобки — через выражение.
Для проверки правильности расчёта, используем обычный eval, заменив все скобки на круглые.
Сделав этот пример, я был доволен, как стадо слонов, но потом решил проверить, а что будет, если скобки расставлены неправильно?
str = "1 + 2 * (3 - 4 / {5 + 6} + [7 - 8 * (9 + 10 * 11) + 12 * {13 - 14]} + 15) + 16 * (17 + 18)"
re = %r{
(?<fill>[0-9+\-*/\s]+){0}
(?<expression>\g<fill>*\g<brackets>\g<fill>*|\g<fill>){0}
(?<braces>\{\g<expression>+\}){0}
(?<squarebrackets>\[\g<expression>+\]){0}
(?<parentheses>\(\g<expression>+\)){0}
(?<brackets>\g<braces>|\g<squarebrackets>|\g<parentheses>)
}x
str =~ reИ я не смог дождаться завершения работы оператора =~ для такого длинного выражения. Это, конечно, неприятно. В причины я вникал не особо, но похоже, это связано с поведением недетерминированной машины Тьюринга. По крайней мере вот ответ на похожую проблему. Для нас это всего лишь означает, что проверять правильность расстановки скобок нужно отдельно и другим способом. Чем я предлагаю заняться пытливому читателю самостоятельно.
Материалы для самостоятельного изучения
- Исходный код статьи.
- Новый синтаксис и прочие вкусняшки в руби 1.9. Для тех, кто заметил =->.
- Глобальные переменные с непонятными именами. Для тех, кто заметил $~.
- Ещё немного базовых приёмов в регулярных выражениях руби.
05.11.2010Ротация логов рельсового приложения

Введение
Это уже давно известная тема, и я не претендую на открытие Америки, но для себя зафиксирую это знание.
Даже если вы используете капистрано для выкладывания проекта в сеть, логи приложения хранятся в одном и том же месте (папка shared/log и разрастаются до огромных размеров. Можно, конечно, запускать после каждого обновления файлов проекта комманду:
rake log:clearНо есть более цивилизованные методы. Тем более, после определённого времени код проекта начинает обновляться всё реже и реже.
С помощью системы
Существует прекрасный системный инструмент, который назвается logrotate. С его помощью архивируются логи апача, баз данных и даже менеджера пакетов.
Чтобы организовать это удовольствие для своего проекта нужно создать файл /etc/logrotate.d/my_project:
/path/to/my_project/shared/log/*.log {
weekly
missingok
rotate 10
nomail
compress
delaycompress
sharedscripts
postrotate
touch /path/to/my_project/current/tmp/restart.txt
endscript
}Здесь написано:
- weekly — разбивать лог еженедельно;
- missingok — не выходить с ошибкой, если файла нет;
- rotate 10 — хранить 10 предыдущих томов;
- nomail — не высылать удаляемые тома на электронную почту;
- compress — архивировать;
- delaycompress — архивировать не сразу, т.к. после переименования файла и до перезапуска пэссенджера логи пишутся в тот же переименованный файл;
- sharedscripts — запускать скрипт один раз для всех логов по маске;
- postrotate...endscript — скрипт, который нужно запустить после ротации: в данном случае перезапустить пэссенджер.
Файлом должен владеть root:root. Теперь можно проверить и запустить принудительно, убедившись, что наш файл включается в общий список:
sudo logrotate -dv /etc/logrotate.conf
sudo logrotate -fv /etc/logrotate.confС помощью руби
В руби есть встроенный метод ротации логов. Достаточно в файе config/environment.rb написать внутри блока Rails::Initializer.run один из вариантов:
config.logger = Logger.new(config.log_path, "weekly")или
config.logger = Logger.new(config.log_path, 10, 1.megabyte)Первый вариант осуществляет ротацию раз в неделю, а второй — по достижении файлом размера в 1 мегабайт и хранит 10 старых томов. Только в данном случае архивацию, если она нужна, придётся организовывать отдельно.
Было бы интересно
Для логротейт можно написать такую маску, которая бы включала в себя все логи всех рельсовых проектов. Но мне неизвестен способ потом написать такой скрипт, который бы перезапускал именно те проекты, для которых была сделана ротация. Например, если логротэйт не нашёл нужного файла, то и скрипт не запустит. А если мы указываем путь типа /path/to/*/shared/.log, то и скрипт должен перебирать все эти проекты и создавать или просто менять дату редактирования файлов restart.txt. Или можно просто перезапускать апач.
Материалы для самостоятельного изучения
20.10.2010Определение, запущен ли процесс
Пролог
Ого! Уже три месяца я ничего не писал в этот блог! Лето выдалось жаркое не только на погоду. Поскольку летом погода лучше, а световой день длиннее, было много работы. Причём работы связанной с поддержкой того, что уже и так нормально функционировало в прошлом сезоне. Ничего серьёзно нового не писалось активно, а значит и захватывающих сюжетов для статей не находилось.
Но теперь у меня появилась возможность писать кое-что новое. Поэтому есть, что рассказать.

Введение
Если вы любите процессы-демоны, как люблю их я, то, возможно, перед вами уже возникала задача определить, запущен ли уже такой демон, перед тем как создавать дочерний процесс. Об этом и будет сегодняшняя статья.
Баш в помощь
Предположим, что у нас есть простейший демон. Хорошо бы имя у него было уникальное, чтобы можно его потом было отыскать. Файл uniq_name_simple_daemon:
#!/usr/bin/env ruby
pid = fork do
begin
running = true
Signal.trap("TERM") do
running = false
end
while running
sleep 0.01
end
rescue Exception => e
puts e.to_s
puts e.backtrace.join "\n"
ensure
exit!
end
endМы всегда можем запускать с помощью другого скрипта, например на баше (simple_daemon_runner.sh):
#!/bin/bash
if ps ax | grep uniq_name_simple_daemon | grep -vq grep
then
echo "uniq_name_simple_daemon is already running"
else
echo "starting uniq_name_simple_daemon"
./uniq_name_simple_daemon
fiНа подобной команде будут базироваться все наши последующие методы. Тут, если кто не понял, мы фильтруем вывод ps ax сначала ища там имя нашего скрипта, а затем исключая из списка сам процесс поиска (команду grep). Ключ q позволяет нам получить код выхода, не выводя ничего на экран. То есть если строчка найдена, то запускаем первый блок, если нет, то второй.
Можно сделать такой же скрипт для остановки процесса (simple_daemon_stopper.sh):
#!/bin/bash
pid=$(ps ax | grep uniq_name_simple_daemon | grep -v grep | awk '{ print $1; }')
if [[ -n $pid ]]
then
echo "stopping uniq_name_simple_daemon"
kill -TERM $pid
else
echo "nothing to stop"
fiКонечно же, при таком раскладе всегда есть возможность запустить нашего демона без помощи скриптов. И тогда проверка делаться не будет. В таком случае полезно проверять, запущен ли процесс уже внутри самого руби, перед тем, как отпочковать дочерний процесс.
Сам себе хозяин
В данном случае задача сводится к проверке наличия в памяти ещё одного процесса с таким же именем кроме текущего. Так же нужно уметь останавливать процесс с помощью того же файла. Вот, какое решение получилось у меня (uniq_name_auto_daemon):
#!/usr/bin/env ruby
ps_ax = `ps ax | grep #{File.basename(__FILE__)} | grep -v grep`.split("\n").map{ |l| l.strip.split(/\s+/) }.reject{ |l| l[0].to_i == Process.pid }
if ps_ax.any?
case ARGV[0]
when /stop/i
ps_ax.each do |l|
system "kill -TERM #{l[0]}"
end
when /kill/i
ps_ax.each do |l|
system "kill -KILL #{l[0]}"
end
else
puts "#{File.basename(__FILE__)} is already running. If you want to stop it, run './#{File.basename(__FILE__)} stop|kill'"
end
else
pid = fork do
begin
running = true
Signal.trap("TERM") do
running = false
end
while running
sleep 0.01
end
rescue Exception => e
puts e.to_s
puts e.backtrace.join "\n"
ensure
exit!
end
end
endВо-первых, обходимся одним файлом, который никак иначе не запустить. Во-вторых, нигде не нужно хардкодить его имя. По-моему, очень удобно.
Оффтопик
С одной стороны, когда я пишу текст, то мне удобнее писать все термины по-русски и склонять их: «демоны», «руби», «баш», но с другой стороны это не поможет тому, кто будет искать решение похожей задачи.
Внутри примеров кода — наоборот, удобнее писать комментарии и тексты по-английски, чтобы не переключать раскладку, но как-то это не очень соответствует русскоязычном блогу.
Что же делать? :)
Материалы для самостоятельного изучения
01.06.2010Работа над ошибками

Введение
Основной целью этого блога является сбор в одном удобном месте необходимых мне по работе знаний и фишек. Однако, именно потому что это активно используемые в работе решения, со временем появляется более продуктивный или более правильный способ сделать то, о чём написано почти в каждой статье.
Иногда я просто ошибаюсь. Трудно представить что-то более полезное для опыта, нежели набивание шишек. Будет хорошо, если проведение работ над ошибками станет доброй традицией. Итак, в этом году.
git hooks
Недостатков скрипта для удаления пробелов в концах строк нашёл два:
- Скрипт без нужды дёргает ни в чём не повинные файлы, потому что \s соответствует и символу конца строки, который там всегда есть.
- Скрипт не содержит решения для выбора всех текстовых файлов проекта.
Вот хороший скрипт:
#!/usr/bin/env ruby
`git grep -I --name-only -e ""`.split("\n").each do |p|
lines = File.readlines(p).map(&:chomp)
if lines.inject(false) { |memo, l| l.gsub!(/\s+$/, "") || memo }
File.open(p, "w") do |f|
f.puts lines.join("\n")
end
puts "Removed trailing spaced from '#{p}'"
system "git add #{p}"
end
endТак же по совету Дмитрия в комментариях добавил скрипт для проверки счастливого коммита.
Работа с версией в (ai)rake
Совершенно очевидная ошибка в примере про работу с версиями air-приложения в rake. Когда увеличивается более старшая часть версии, то все младшие должны обнуляться:
namespace :version do
[:major, :minor, :patch].each_with_index do |subv, index|
desc "Bump #{subv} in version"
task :"bump_#{subv}" do
unless `git status` =~ /nothing to commit/
raise "There are uncommitted changes. Failed to proceed."
end
appxml = YAML.load_file('airake.yml')["appxml_path"]
str = File.read(appxml)
msg = nil
new_version = nil
if str.gsub! /<version>(.*)<\/version>/ do |matched|
old_version = $1
major, minor, patch = old_version.split(".").map(&:to_i)
eval("#{subv} += 1")
new_version = [major, minor, patch].fill(0, index+1).join(".")
msg = "Version bump #{old_version} => #{new_version}"
puts msg
"<version>#{new_version}</version>"
end.nil?
raise "Cannot detect current version.\nMake sure appxml file contains <version>X.X.X</version> tag."
else
File.open(appxml, "w") do |f|
f.write str
end
puts `git commit -am "#{msg}"`
puts `git tag v#{new_version}`
end
end
end
endТеперь rake version:bump_minor делает из 0.1.6 не 0.2.6, а 0.2.0, как и должно быть.
Мимоходом
Тем временем я сменил тарифный план у своего провайдера на (ve). И незаметно перенёс сайт. Посмотрим, как работает на собственном опыте. Работа по ssh, как была, так и осталась основным способом администрирования, а необходимость лазить в plesk пропала, потому что его теперь нет :)
26.05.2010Использование git hooks на руби в корыстных целях

Введение
Как-то раз мне попался очень злой git-репозиторий, который отказывался работать, если я оставлял пробелы в конце строк. Есть такая версия, что git заточен под отправку патчей по почте, и что пробелы в концах строк могут навредить в таком процессе.
Тогда я просто отключил эту проверку, а недавно подумал, почему бы мне не использовать эти мощности в мирных целях.
git hooks
Для множества различных целей у git есть хуки. (Как бы их перевести нормально?) Они находятся в каждом репозитории в папке: .git/hooks
И имеют говорящие названия. Используются они для соблюдения форматов и соглашений, для оповещений, для проверки и т.п. Почему бы не возложить на них корректорские функции?
Использование pre-commit для удаления пробелов на концах строк
Поскольку я, опять же, фанат руби, то и скрипты — благо есть такая возможность — напишу на руби. Создаём файлик .git/hooks/pre-commit:
#!/usr/bin/env ruby
Dir.glob("*.{txt,rb}").each do |p|
lines = File.readlines(p)
if lines.inject(false) { |memo, line| line.gsub!(/\s+$/, "") || memo }
File.open(p, "w") do |f|
f.puts lines.join("\n")
end
system "git add #{p}"
end
endКак видно, этот скрипт ищет файлы *.txt и *.rb в корневом каталоге репозитория, и если в них есть пробелы в конце строк, перезаписывает их и добавляет в индекс для коммита.
Не забыть сделать его запускаемым:
chmod +x .git/hooks/pre-commitТеперь у нас в распоряжении автоматический помощник-редактор, который удаляет пробелы в конце строк.
Материалы для самостоятельного изучения
28.04.2010Использование Airake под Kubuntu
Введение
Уже некоторое время назад обнаружил гениальный инструмент. Правда только недавно опробовал его на своих рабочих проектах и зафанател ещё больше. Подготовка к докладу на секции Яндекса про панорамы на РИФе не позволила мне поделиться этим ранее. Исправляю ошибку.
Я люблю руби. И, естественно, rake, как инструмент, продолжающий славные традиции make в руби и с помощью руби. Так же я питаю нежные чувства к ActionScript. Мне нравится AIR, который позволяет писать действительно кросс-платформенные приложения довольно быстро. Так же я неплохо отношусь к TDD, как к одному из способов разработки.
Какова же была моя радость найти инструмент, который всё это объединяет! Хотя ему уже пара лет, он по-прежнему прекрасен.
Установка составляющих
Предполагаю, что ruby, rubygems и rake уже установлены у тех, кто читает этот блог.
Далее, качаем и разархивируем куда-нибудь Adobe AIR SDK и Adobe Flex SDK (или предыдущая версия, если вы консерватор), а так же устанавливаем Adobe AIR Runtime. Чтобы установить последний, после загрузки bin-файла нужно:
chmod +x AdobeAIRInstaller.bin
sudo ./AdobeAIRInstaller.binТеперь добавим в PATH пути к исполняемым файлам загруженных SDK. В .bashrc добавляем:
export PATH="/path/to/air_sdk/bin:$PATH"
export PATH="/path/to/flex_sdk_4/bin:$PATH"Так же потребуется установить java для того, чтобы на ней работал компилятор:
sudo apt-get install sun-java6-jreПосле установки, независимо от того, используете вы Flex3 или Flex4, нужно переписать содержимое AIR SDK поверх Flex SDK. Мне не совсем понятен сакральный смысл этих действий, но иначе ничего не работает.
Привѣтъ, Мiръ!
Создание пустого air-приложения теперь просто:
airake airake_hello_worldЧтобы запустить его, однако, следует исправить в src/AirakeHelloWorld-app.xml и test/Test-app.xml:
...
xmlns="http://ns.adobe.com/air/application/1.5"
...Если вы решили использовать Flex4, то вам необходимо отредактировать сгенерированное приложение, чтобы запустить его. Это связано с изменениями в стилях. Поэтому проще просто удалить всё содержимое тэга WindowedApplication в файле src/AirakeHelloWorld.mxml.
Про использование TDD в ActionScript я уже писал, поэтому подробно останавливаться не буду. Для примера в код на github включён тривиальный тест. Запуск тестирования происходит привычным образом:
rake testДокументация, если вы пишете правильные комментарии ASDoc, тоже запускается привычным образом:
rake docsТак же делается всё остальное: запуск приложения в отладочном режиме, генерирование сертификата, упаковка релиза приложения. Для того, чтобы это всё узнать, используйте:
rake -TИспользование rake
Конечно, вся прелесть rake не только в привычных и коротких командах для разработки, но и в том, что можно создавать свои сценарии. Например, вот как могла бы выглядеть работа с версиями приложения. Добавим в файл raketasks/version.rake следующий код:
require 'yaml'
desc "Print out current version"
task :version do
if md = File.read(YAML.load_file('airake.yml')["appxml_path"]).match(/<version>(.*)<\/version>/)
puts "Current version is #{md[1]}"
else
raise "Cannot detect current version.\nMake sure appxml file contains <version>X.X.X</version> tag."
end
end
namespace :version do
[:major, :minor, :patch].each do |subv|
desc "Bump #{subv} in version"
task :"bump_#{subv}" do
unless `git status` =~ /nothing to commit/
raise "There are uncommitted changes. Failed to proceed."
end
appxml = YAML.load_file('airake.yml')["appxml_path"]
str = File.read(appxml)
msg = nil
new_version = nil
if str.gsub! /<version>(.*)<\/version>/ do |matched|
old_version = $1
major, minor, patch = old_version.split(".").map(&:to_i)
eval("#{subv} += 1")
new_version = [major, minor, patch].join(".")
msg = "Version bump #{old_version} => #{new_version}"
puts msg
"<version>#{new_version}<\/version>"
end.nil?
raise "Cannot detect current version.\nMake sure appxml file contains <version>X.X.X</version> tag."
else
File.open(appxml, "w") do |f|
f.write str
end
puts `git commit -am "#{msg}"`
puts `git tag v#{new_version}`
end
end
end
endА в Rakefile соответственно:
# Custom rake tasks
Dir.glob("raketasks/*.rake").each { |rf| load rf }Теперь мы можем привычным образом работать с версиями приложения (а версии эти потом будут распознаваться установщиком обновлений):
rake version
rake version:bump_major
rake version:bump_minor
rake version:bump_patchИ это не предел!
Материалы для самостоятельного изучения
- Полный код статьи на github
- Инструкция по работе с airake, которая во многом повторена в этой статье с добавлением манипуляций, чтобы всё заработало.
- Документация по FlexUnit. Не уверен, что в поставке airake идёт самая последняя версия, но ничего не мешает написать rake task для обновления версии FlexUnit :)
- Документация по rake
07.04.2010Немного о $SAFE

Введение
Совершенно не по работе заинтересовался переменной $SAFE и её ролью в жизни современного разработчика. Оказалось, что всё нужно проверять самому.
Нежная безопасность
Для тестирования возможностей на разных уровнях безопасности собрал небольшую программку. Она просит ввести имя файла, делая строковую переменную небезопасной, и пытается что-то с этим всем сделать.
print "child: "
child = gets.chomp
puts "child tainted: #{child.tainted?}"
(0..4).to_a.each do |i|
puts "SAFE: #{i}"
$a = "safe"
th = Thread.new do
$SAFE = i
child_copy = child.dup
Thread.current[:out] = ""
begin
load child_copy
Thread.current[:out] += "1. Child loaded\n"
rescue SecurityError => e
Thread.current[:out] += "1. Security error: #{e.to_s}\n"
begin
child_copy.untaint
load child_copy
Thread.current[:out] += "2. Child untainted and loaded\n"
rescue SecurityError => e
Thread.current[:out] += "2. Security error: #{e.to_s}\n"
begin
Thread.current[:out] += "3. Read from file '#{child_copy}': '#{File.read(child_copy)}'\n"
rescue SecurityError => e
Thread.current[:out] += "3. Security error: #{e.to_s}\n"
begin
Thread.current[:out] += "4. Read from untainted file: '#{File.read("child.rb")}'\n"
rescue SecurityError => e
Thread.current[:out] += "4. Security error: #{e.to_s}\n"
end
end
end
end
begin
$a = "modified"
Thread.current[:out] += "5. Global variable modified: $a = '#{$a}'\n"
rescue SecurityError => e
Thread.current[:out] += "5. Security error: #{e.to_s}\n"
end
begin
Dir.mkdir "test"
Thread.current[:out] += "6. Created directory 'test': #{File.exist?("test")}\n"
Dir.rmdir "test"
rescue SecurityError => e
Thread.current[:out] += "6. Security error: #{e.to_s}\n"
end
begin
Thread.current[:out] += "7. Dir glob: #{Dir.glob(File.join("..", "*")).inspect}\n"
rescue SecurityError => e
Thread.current[:out] += "7. Security error: #{e.to_s}\n"
end
begin
Thread.current[:out] += "8. System ls output: '#{`ls`.chomp}'"
rescue SecurityError => e
Thread.current[:out] += "8. Security error: #{e.to_s}\n"
end
end
th.join
puts "Global variable: $a = '#{$a}'"
puts th[:out] if th[:out]
endКонструкция со Thread.current[:out] используется потому, что для $SAFE >= 4 нельзя ничего писать ни в какие устройства вывода.
Вроде бы всё логично. Первый уровень годится для умеренного карантина внешних данных. При желании их можно и расколдовать. Второй уровень запрещает изменения в файловой системе. Третий уровень похож на осаду с постоянным подозрением на шпионаж. Все созданные объекты считаются небезопасными. А четвёртый уровень — это самое близкое к песочнице (sandbox) в руби, что что есть.
Кстати, когда ещё github работал как репозиторий библиотек, спецификация gemspec выполнялась там под $SAFE = 3. Для разработчиков это выливалось в то, что нужно было перечислять все файлы своей библиотеки вручную вместо использования какого-нибудь листинга.
Суровый гайдлайн
Конечно же, только использование $SAFE не убережёт от действительно настойчивой атаки или блокирующего кода. Например:
Thread.new do
$SAFE = 2
class String
def ==(other_string)
true
end
end
end.join
puts "string modified: #{'a' == 'b'}"И это на втором уровне! А на третьем открыть класс тоже можно, но вызов перегруженного оператора будет вызывать SecurityError.
На сегодняшний момент эту концепцию безопасности можно считать сырой. Актуальное поведение руби 1.8 слегка отклоняется от описаний, что я нашёл. Поведение в 1.9 изменилось, но подробно нигде не описано (я не нашёл).
Это не значит, что этой переменной нет применения в жизни прогрессивного человечества. Адекватное текущему состоянию применение — это гайдлайн при разработке. Руководство для программистов, которое само следит за своим исполнением. Жестковато, но зато действенно. :)
Материалы для самостоятельного изучения
- Код примеров в статье на github
- Старая, но самая подробная документация по $SAFE
- Просто дополнительно: шпаргалка по руби